
AI systems don’t fail because the models are weak. They fail because evaluation doesn’t scale.
Every successful system depends on domain experts. They know what “good” looks like, and their validation is the foundation of trust. But there’s a paradox: experts are indispensable yet scarce.
But expert validation is slow, expensive, and exhausting. Organisations cannot afford to keep pouring hours of senior expertise into reviewing every single output forever.
That’s why at Faktion, we build AI systems equipped with Evaluator Agents (LLM-as-Judge models) that learn directly from expert feedback from day one.
Early on, experts validate outputs: right or wrong, complete or incomplete, relevant or off-track. Those signals are used to design and align evaluator agents with the domain experts' evaluation. Over time, and as human and agent evaluation become more and more aligned, the evaluator agent steps in and takes over responsibility from the domain experts.
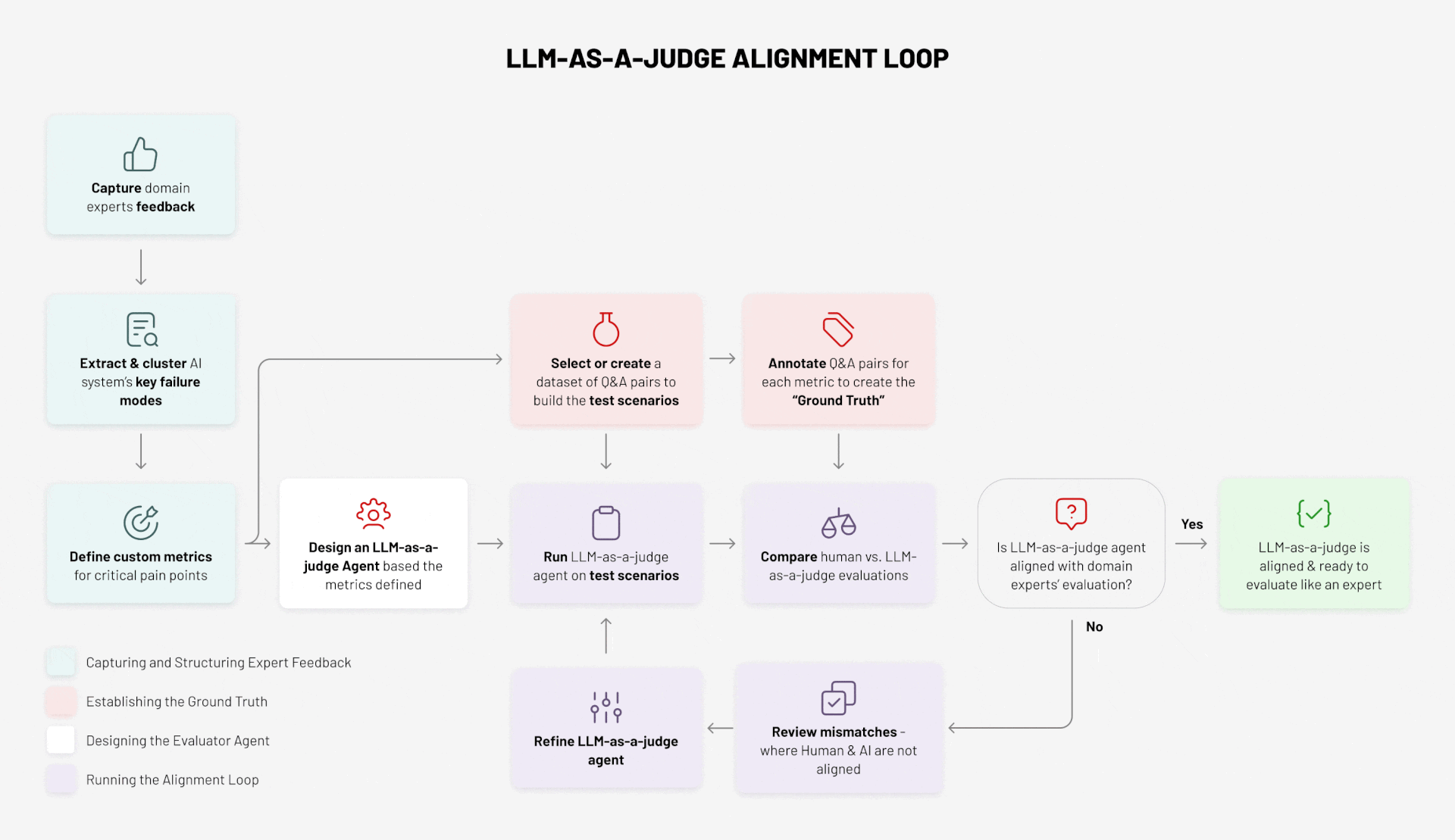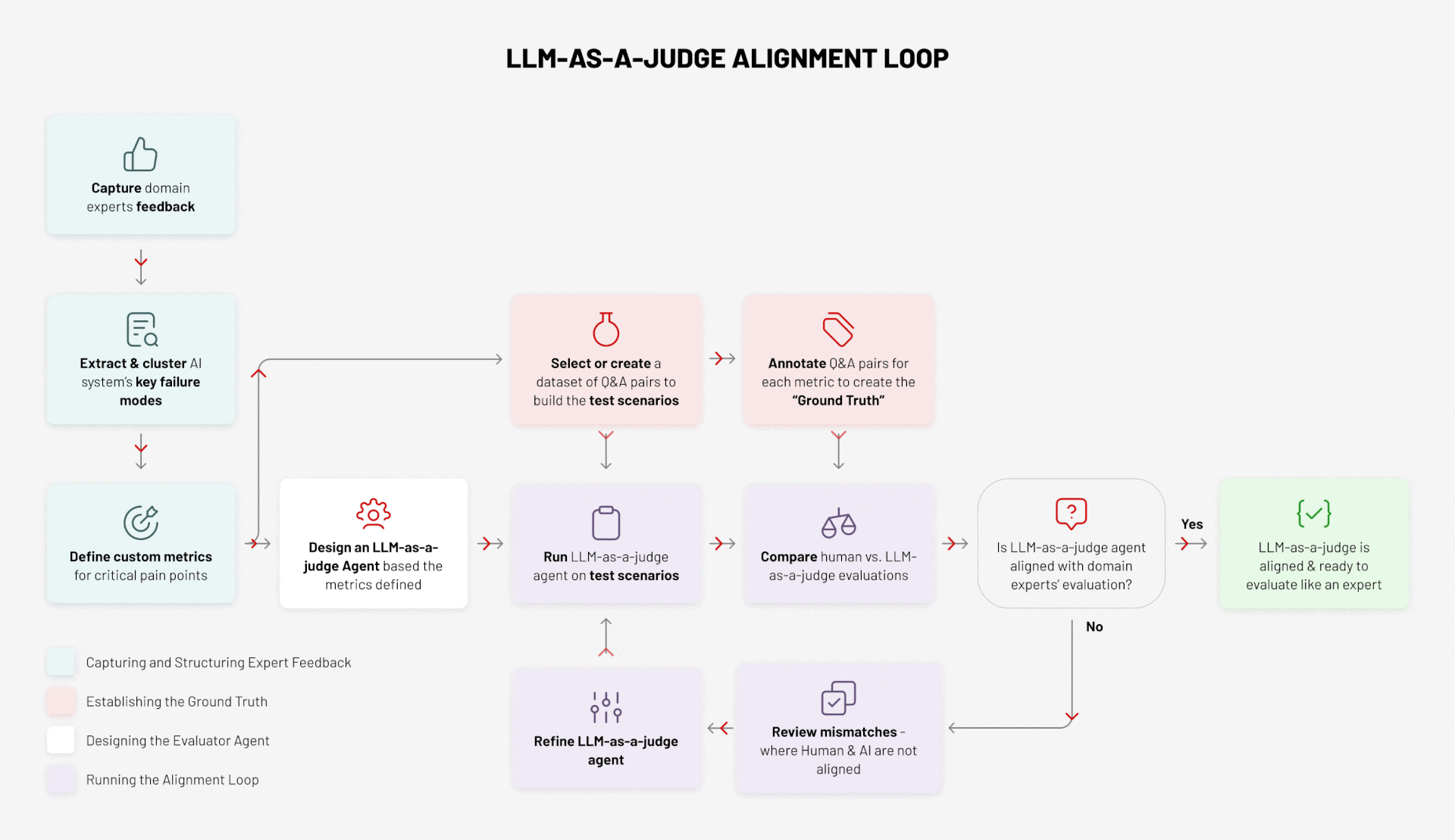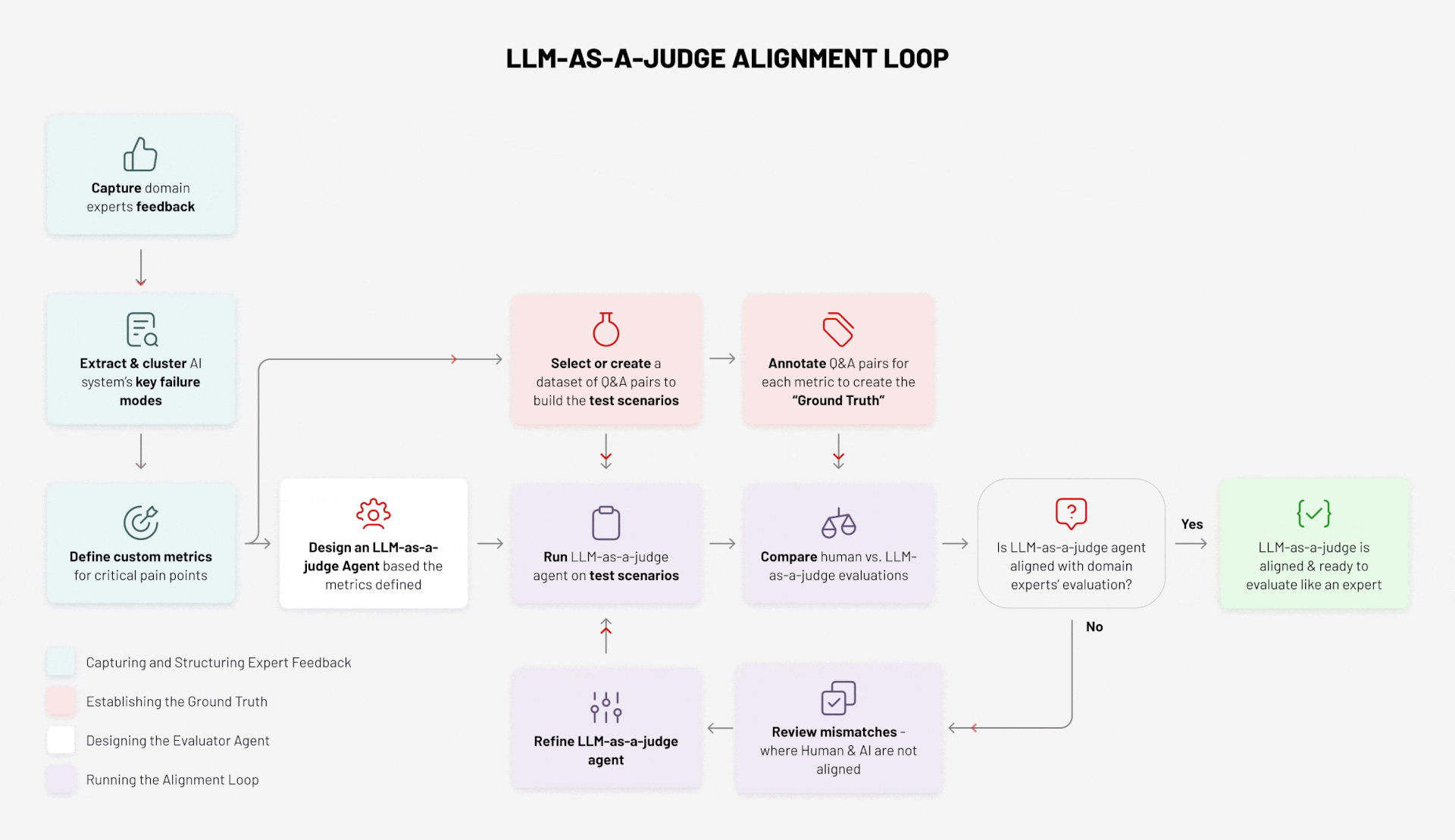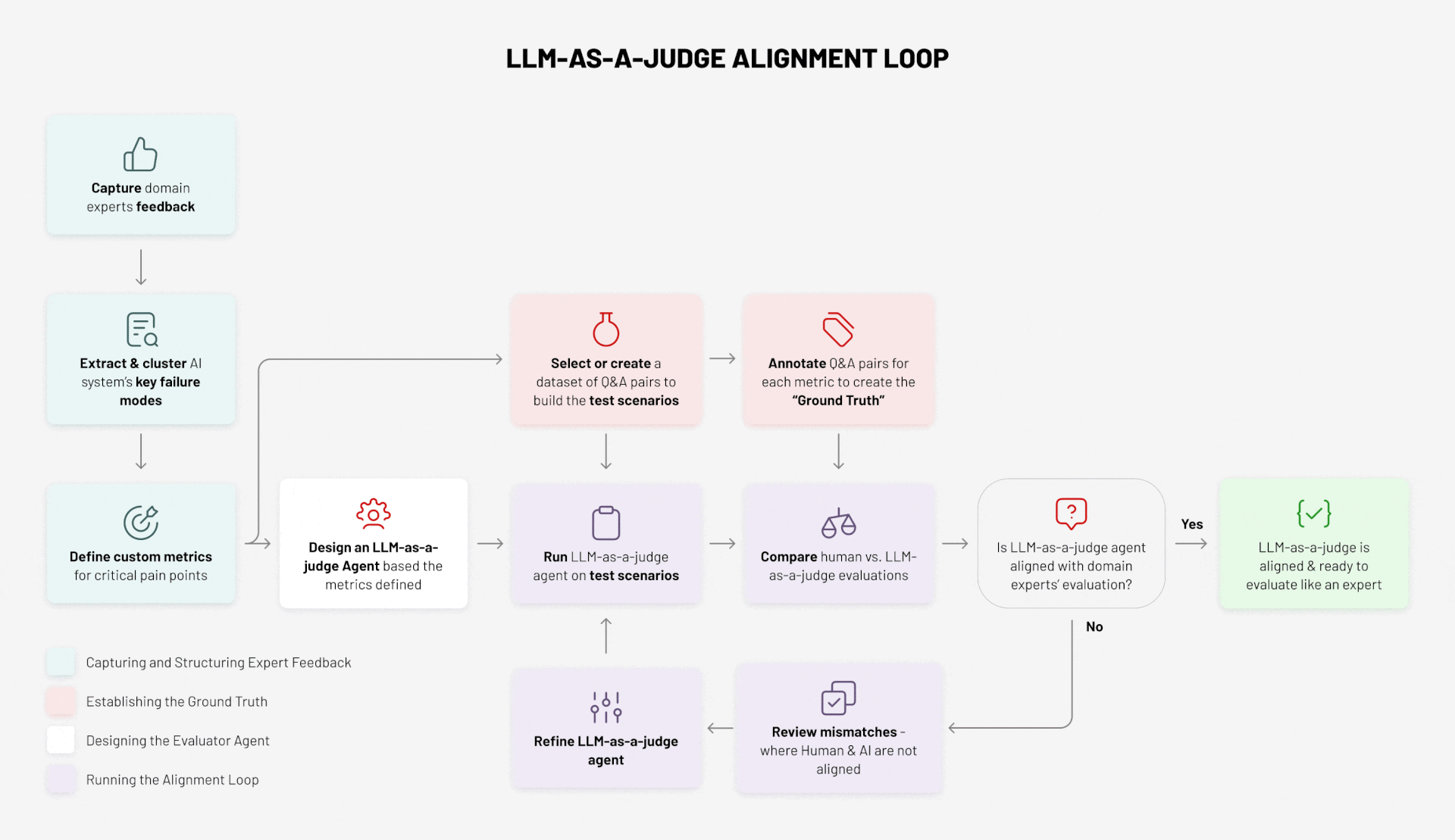
Here’s how the process works, structured across four key activities:
- Capturing and Structuring Expert Feedback
- Establishing the Ground Truth
- Designing the Evaluator Agent
- Running the Alignment Loop
In this blog post, we go deeper in each key activity and explain the steps that need to be taken in detail.
Capturing and Structuring Expert Feedback
The starting point of every evaluation loop is human expertise. Without it, there is no “ground truth.”
Step 1: Capture Expert Feedback
The process starts with domain experts. They evaluate outputs, flag errors, and highlight gaps. Their feedback is the raw material for everything that follows. Without this step, there is no “ground truth” to anchor evaluation.
Step 2: Extract and Cluster Failure Modes
Not all errors are equal. By analysing feedback, we identify the system’s recurring failure modes:
- Incomplete answers
- Hallucinations
- Outdated references
- Wrong citations
- Overly generic responses
Clustering these issues allows us to focus on the critical pain points that matter most to users.
Step 3: Define Custom Metrics
From failure modes, we define metrics that capture what “good” looks like in the given business domain. For example:
- Completeness: Did the response cover all required elements?
- Relevance: Is it aligned with the query’s intent?
- Accuracy: Are the citations valid and up to date?
These metrics ensure evaluation is specific, not just “thumbs up or down.”
Establishing the Ground Truth
Once metrics are defined, we need a reliable reference dataset that reflects reality. This is where domain experts play their most important role.
Step 4: Curate a Dataset of Q&A Pairs
Once metrics are in place, we need a benchmark dataset that represents reality. This means selecting or creating Q&A pairs that capture real-world use cases:
- Historical support tickets.
- Customer service transcripts.
- Internal process documentation.
- Edge cases designed specifically to test system limits.
This curated dataset forms the test scenarios against which evaluation will be performed.
Step 5: Annotate the Dataset to Create Ground Truth
Domain experts then annotate the curated Q&A pairs according to the defined metrics. For each answer, they judge whether it is complete, accurate, relevant, and compliant.
The result is a fully annotated ground truth dataset. This is the reference point against which evaluator agents will be trained and aligned.
Designing the Evaluator Agent
With metrics and ground truth in place, the next step is to build the evaluator itself.
Step 6: Design the Evaluator Agent
With metrics and ground truth in place, we can design an LLM-as-a-Judge agent. This evaluator is built to apply the same metrics that experts use. At this stage it’s still naive — it needs iterative refinement to align with expert judgment.
Running the Alignment Loop
This is where the evaluator agent learns to act like an expert. The process is iterative and continuous.
Step 7: Run the Evaluator Agent on Test Scenarios
The evaluator agent is tested against the curated and annotated dataset. This first run shows how the agent interprets the metrics in practice.
Step 8: Compare Human vs Agent Evaluations
The agent’s scores are compared directly with domain expert annotations:
- When they align, it’s a sign the agent is learning to judge like an expert.
- When they diverge, it signals a gap that needs attention.
This comparison is the heart of the alignment process.
Step 9: Review the Mismatches
Every disagreement between human and agent is reviewed carefully. Possible reasons include:
- Ambiguous ground truth examples.
- Misinterpreted metrics by the agent.
- Weak prompts or flawed scoring logic.
This step reveals whether the problem lies in the dataset, the evaluation logic, or the agent itself.
Step 10: Refine and Repeat
Based on the mismatch review, we refine the evaluator:
- Adjust prompts and instructions.
- Improve the scoring logic.
- Clarify metrics or ground truth if necessary.
The refined agent is then re-run on the test scenarios, and the cycle repeats until the evaluator consistently aligns with domain expert judgment.
The Outcome
When evaluator agents are properly designed, aligned, and deployed, the payoff is significant, both for the experts involved and for the organisation as a whole.
- Experts remain the source of truth but they don’t carry the burden forever.
- Evaluation becomes continuous and scalable not a one-off workshop.
- The AI system keeps improving, guided by evaluator agents that replicate expert judgment.
This loop transforms AI from fragile prototypes into production-ready systems that users can trust.
At Faktion, we design evaluation into the system from day one, creating workflows where experts define the standard, and evaluator agents scale it across the organisation. That’s how AI earns trust and delivers long-term ROI.
Reliable AI isn’t just about assistants that generate answers. It’s about judges that keep those answers honest.











.avif)







