

Trial and error
The reason these agents can achieve super-human performance can be brought back to the basic design of RL algorithms. An agent is rewarded when the actions it takes improve the condition or state the agent finds itself in. The actions themselves aren’t judged, just the consequences. Giving the agent the freedom to explore the interaction between its action and state-space focusing just on the outcome. This trial-and-error approach isn’t always computationally efficient, but the recent breakthroughs are testament to just how powerful it can be.
From Atari to industry
Game-based environments have been the bread and butter of RL research for decades. Games can be designed or chosen based on the complexity researchers want to tackle and results are easy to benchmark thanks to open-source efforts like Open AI’s gym standardizing the environment - agent interface. This standardization has been a catalyst for a thriving open-source community that has produced amazing tools like RLlib, which holds a wealth of high-quality state-of-the-art agent implementations. Thanks to these developments the stars are finally aligned for RL to move beyond the world of games. To get started, you no longer have to code agents from scratch, something notoriously hard to do and debug. Instead, you can focus on creating high-quality environments that are digital twins of real-world systems, and clever reward functions that guide your agents to greatness.
The cement mill environment
One of Faktion’s industrial partners introduced us to the cement milling process. In a nutshell, raw resources are ground and mixed inside a huge spinning cylinder containing metal balls. The material flowing out of this grinder is separated into the finished product and insufficiently ground material which is looped back for another passage through the grinder.

We built a digital twin of this process to act as an environment for the RL agent. The task of the agent is to produce as much high-quality output material as possible. An important limiter is the efficiency of the grinder which goes down if too much material is fed into it. Reduced grinding efficiency means that material coming out of the grinder won’t be much more fine-grained than the material that went in. The separator will then return more of the material to the already overloaded grinder which will result in a runaway feedback loop if not dealt with. Aside from the quantity of the output, the reward function also factors in its quality. The mill can produce different types of cement and each type has its own ideal fineness and recipe (proportions of input material in the output). The closer the properties of the output match these ideal values, the higher the reward will be.
When simulating the cement mill in operation the type of cement to produce will be changed regularly, forcing the agent to efficiently adapt the settings of the plant to the new requirements. The plant settings which the agent can adjust are the flow rates of the six input feeders and the fineness threshold used inside the separator to decide if the material is returned to the grinder or not.
Reinforcing desired behavior
Designing a good reward function is crucial in any reinforcement learning system as it will determine which state transitions are reinforced and which are penalized. In our cement mill environment, the reward function is a multiplication of factors that each check a separate metric of the state and return a value between zero and one depending on how close the observation is to the optimum. The plot below shows an example of a single reward multiplier that checks how close the fineness of the output material lies to the optimal value of the cement type that is currently being produced.

Notice that this function has a fairly long tail (i.e. the y-values don't go to zero), this ensures that even when the state is very far from optimal the agent will still notice an improvement when it moves in the right direction. The complete reward function is:
reward = material fineness deviation * recipe delta deviation * grinder efficiency * output material flow rate
Operating the mill
The dashboard below shows live metrics of the process responding to the fully trained agent actions displayed at the top. Every 150 timesteps the type of cement to produce is changed to test the agent’s adaptability.
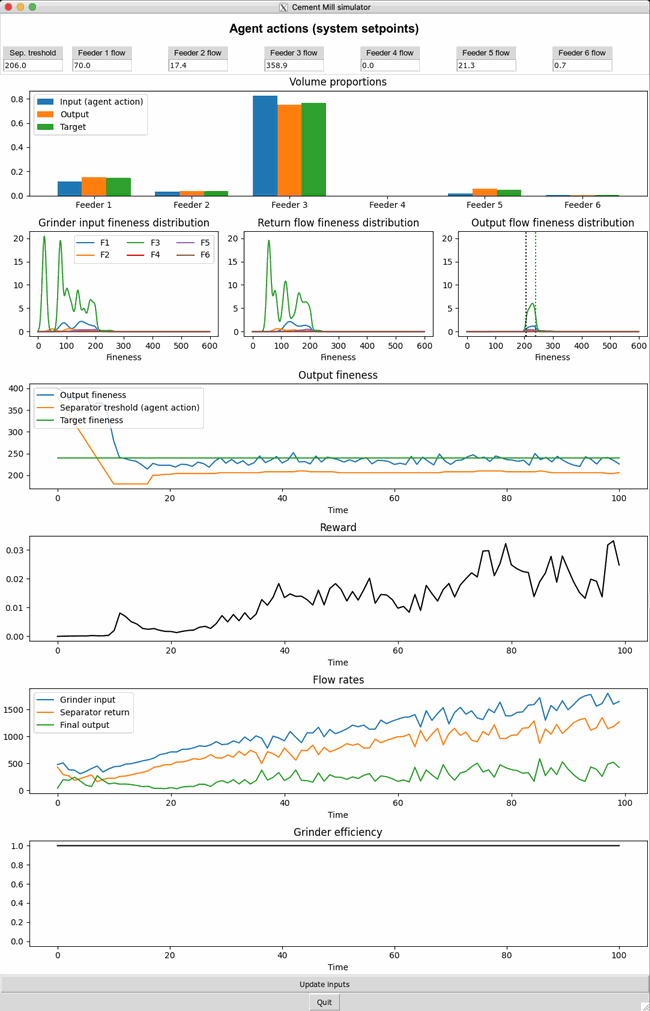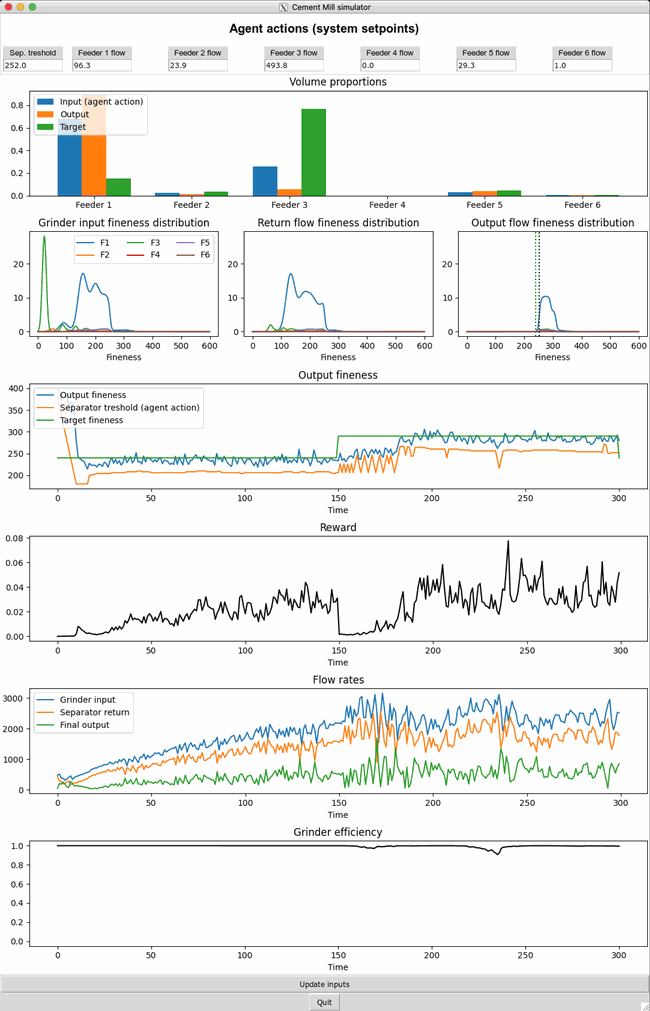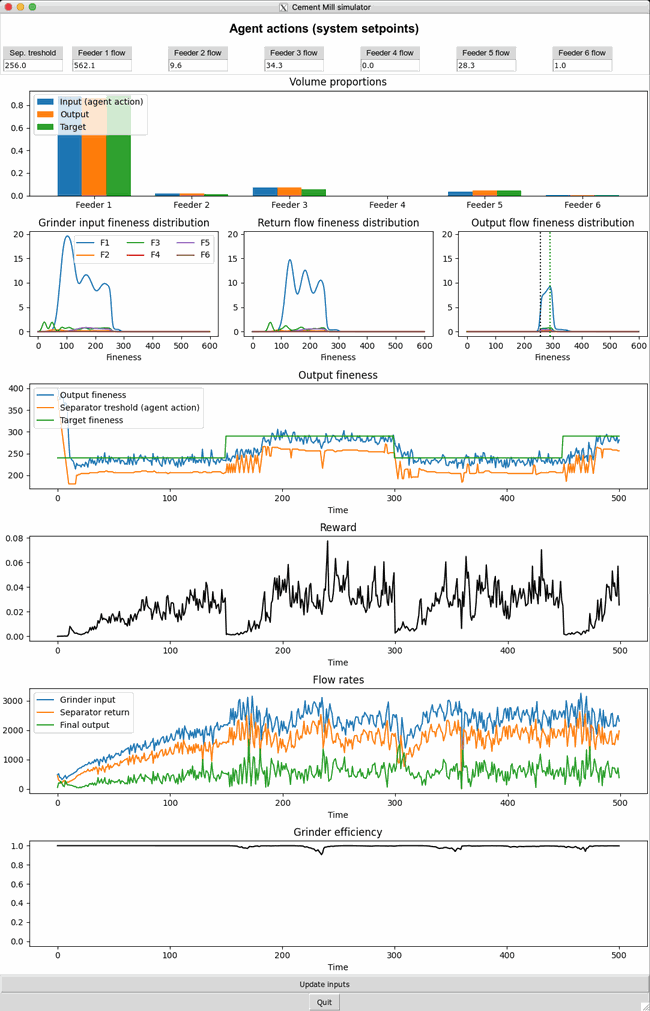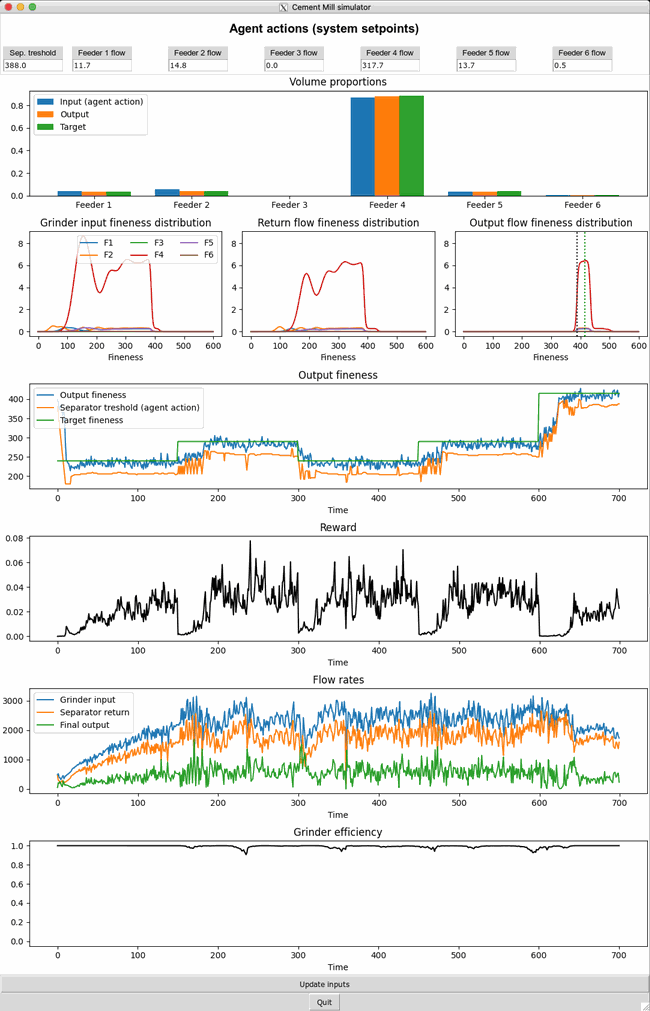
The small dips in grinder efficiency are a signal that the agent is pushing the system to its limit in terms of throughput quantity. The quality of the output is also excellent, meeting both the fineness and recipe requirements. Aside from optimizing both quantity and quality, the agent shows great skill while adapting to changes. At timestep 150 it needs to shift to making a different type of cement with a higher fineness (see green line in the “Output fineness” graph). Instead of directly shifting the fineness threshold of the separator upwards (orange line) it waits for a bit to let the old material with a different recipe pass. Without this precaution, there would have been a surge in material being sent back due to not being sufficiently fine-grained resulting in an overload of the grinder. In summary, the agent has become a skilled operator of the cement mill digital twin.
What’s next?
We’re super excited about the maturing RL field and are already applying the technique to optimize our customer's processes. Do you too manage a complicated process that needs optimizing? Let’s talk!
