

As a 25-strong AI-focused company here at Faktion, we are always concerned about delivering the most accurate and cutting-edge Natural Language Understanding (NLU) models. NLU models are used by some of the largest and most innovative companies in the world for conversational interfaces (chat, voice, e-mail), document classification, mood analysis, script optimization… To underpin the claim that our models are the best, we decided to benchmark our existing NLU model for intent classification against giants of the industry: LUIS from Microsoft, DialogFlow from Google, and Watson Conversation from IBM.
We decided to benchmark previously unbeatable NLU engines against our NLU models for languages that receive little attention. As far as we are aware, no benchmarks exist for Dutch and French NLU models. We are building chatbots in non-English speaking countries, and for our clients, privacy and language-specific nuances are of great importance. Our expertise is mainly in Deep Learning and NLU models where the language is treated as a sequence of words (like utterances and sentences) connected to each other and processed with a Recurrent Neural Nets architecture.
We focused this benchmarking effort on several key aspects. First, we wanted to understand how well all NLU engines are classifying intents for clean Dutch expressions. Second, we benchmarked NLU engines against real-world chatbot expressions used in production systems. Finally, we compare the accuracy of the NLU models for two languages, namely French and Dutch. This gave us a clear insight into the language-specific accuracy of the models in our largest client zones (The Netherlands, Flanders, France, Luxembourg, and Wallonia).
Experimental Setting
Here we define necessary steps to reproduce our results with respect to LUIS, DialogFlow, and Watson NLU engines. We start with data pre-processing and cleaning routines, which can be reduced to the following set of actions.
For expressions:
- Strip the utterance (remove heading and trailing whitespaces).
- For every utterance, replace all EOF, tabs, and newline characters with whitespaces.
- If the total number of characters is >500: split the expression on whitespace and re-join words until the 500-character limit is reached (LUIS API requirement).
- Convert all characters in the expression to lowercase.
For intent labels:
- Strip the intent (remove heading and trailing whitespaces).
- For every intent, replace all non-alphanumeric characters with underscores (Watson API requirement).
- Take only the first 128 characters from every intent name (Watson API requirement).
- Convert all characters in the expression to lowercase.
After these necessary steps were performed on the raw expression data, we proceeded with some additional post-processing steps to ensure the integrity of the input data:
- Remove all duplicates.
- Take only non-empty expressions into account.
Training and test setup
To ensure the reproducibility of the training/test routines, we define here some of the tools, techniques, and methodologies used to split and evaluate the models.
- We used only Python code and Scikit-Learn framework to split the data and evaluate the models.
- We performed a stratified random 5-fold test-train split (data was shuffled) for the chatbot expressions.
- Where possible (e.g., every model run), we set the random seed to 123.
- We ran all the models with default parameters and confidence thresholds.
All test predictions coming from different test-train splits (separately for clean Dutch and production chatbot expressions) were consolidated in the end to one CSV file. For LUIS and Watson NLU engines, we always keep on polling the server for the training procedure to end. All other LUIS and Watson specific API requirements are met as well.
Results
We start with the analysis of clean Dutch expressions which are ideal to quickly verify the predictive power of all NLU engines. Then we proceed to the results for chatbot expressions and their corresponding intent classification.
We present 2 main performance metrics: classification accuracy and F1-score. All results are aggregated separately according to either the intent name or chatbot name. We outline the boxplots of these metrics displaying mean, median, quantiles, and outliers.
The displayed information can be summarized as follows:
- The X-axis represents the NLU-engine dimension with additional accompanying scores denoting:
- weighted average across all scores (weighting is done w.r.t. the number of expressions per intent or chatbot) – the first score in the brackets.
- the median of all scores – the second score in the brackets and the orange line in the boxplot.
- The Y-axis represents the score dimension in the range [0..1]
- In addition to median, quantiles, and fences, the mean score is indicated with a green triangle.
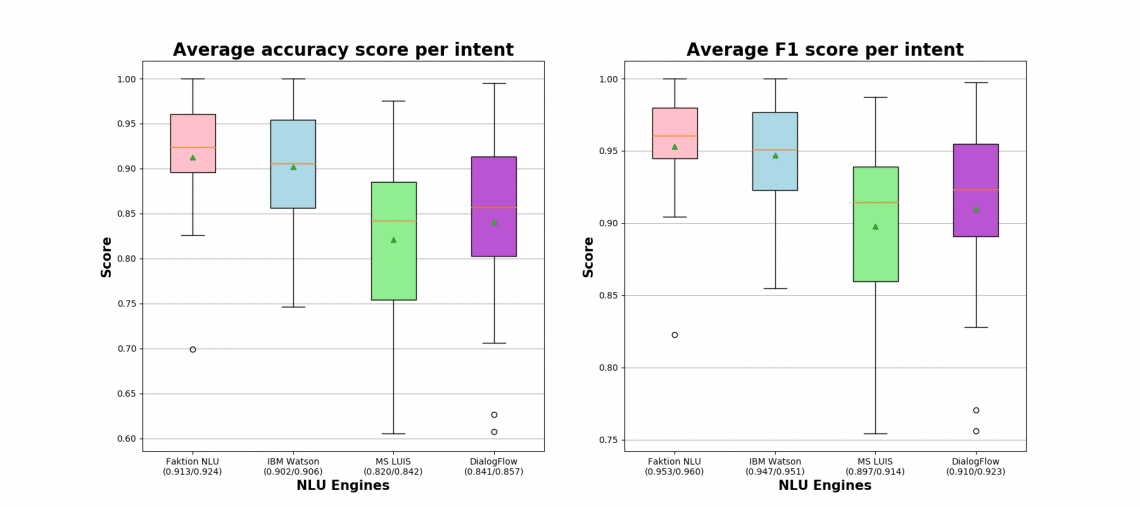
Figures for clean Dutch expressions
The boxplots below represent the classification accuracies and F1-scores per intent for clean Dutch expressions. We can easily recognize that our NLU engine is outperforming LUIS by a large margin and is winning over IBM Watson in terms of overall statistics and variance of results.
Figures for real-world chatbot expressions
Next, we switch to the results for chatbot expressions as less clean and more realistic examples of NLU engines in action. We can still observe a clear win of the Faktion NLU engine over LUIS and a close runner-up by IBM Watson. The first figure denotes results obtained from the Dutch expressions. The second figure represents French chatbot expressions and corresponding classification metrics.
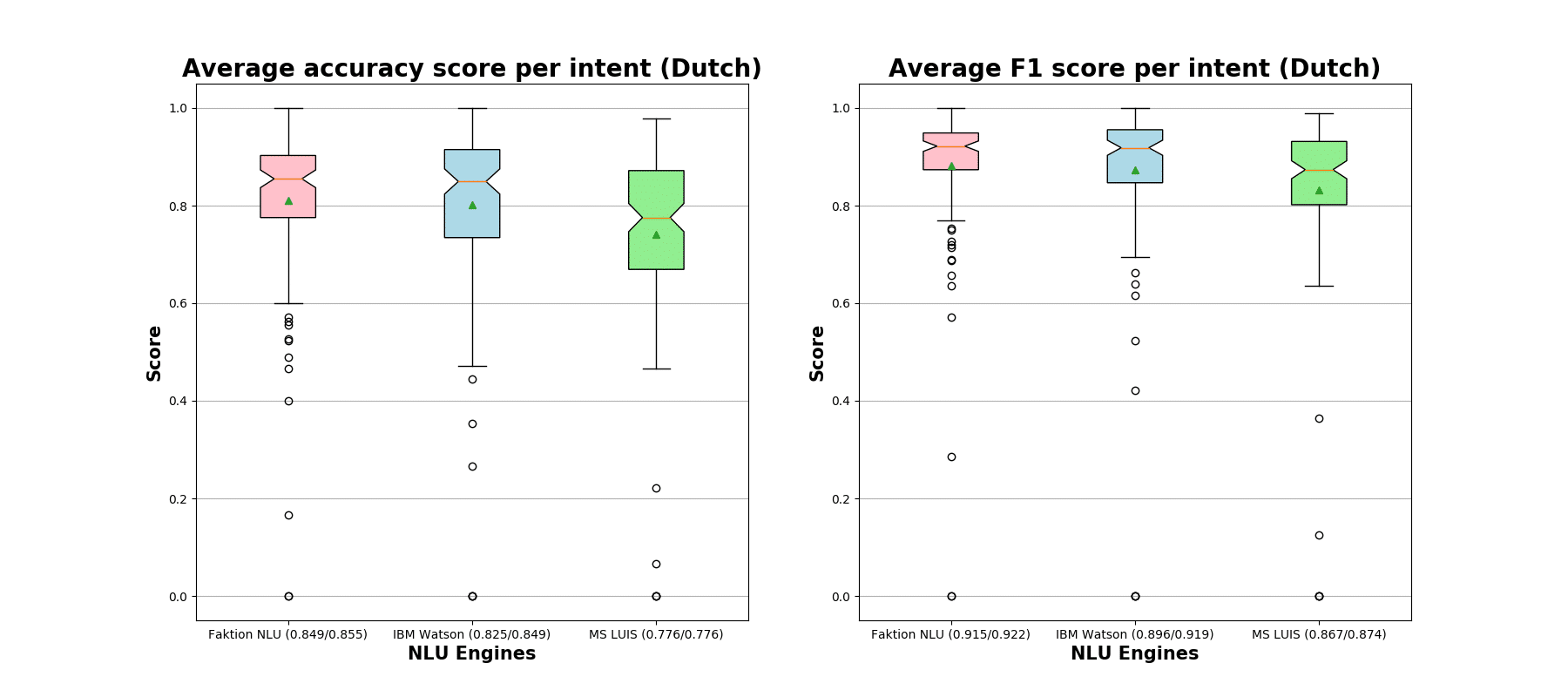
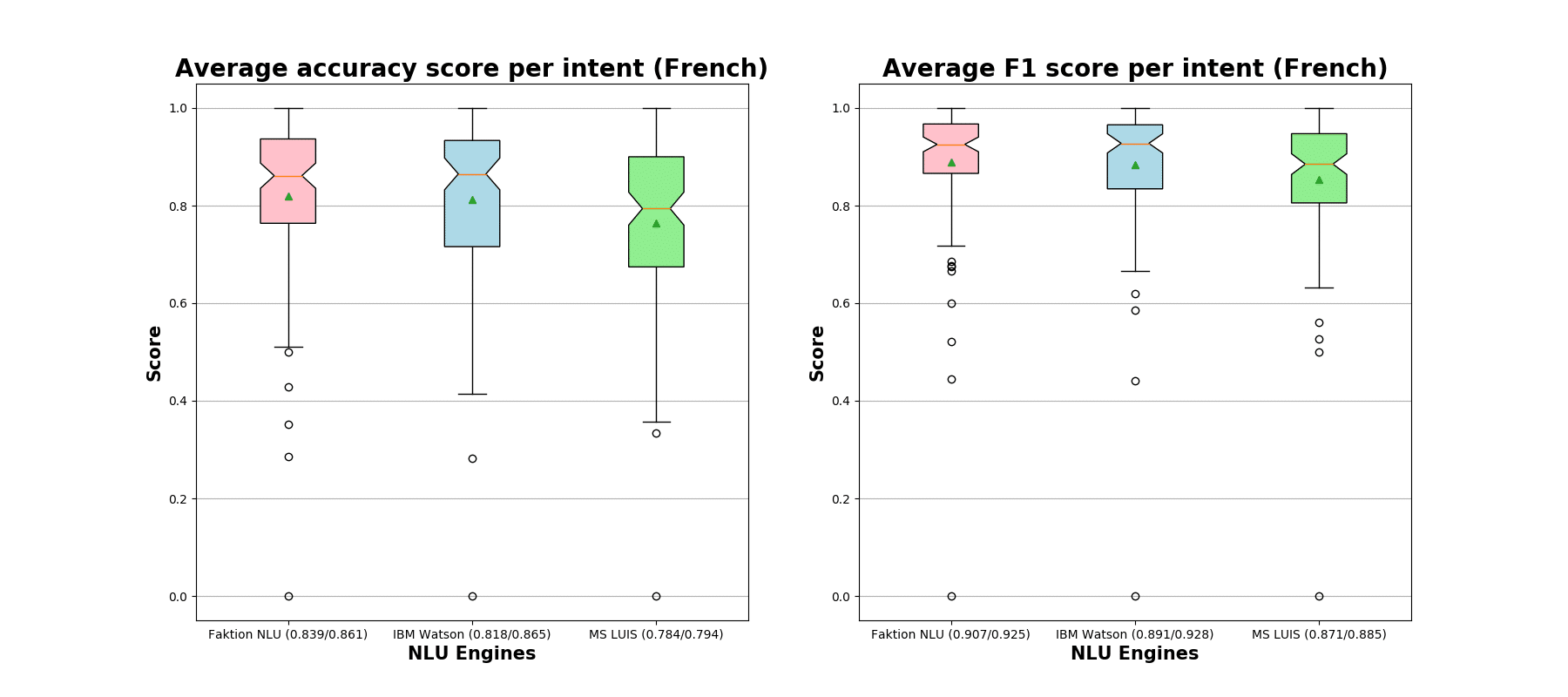
As we can that notice all NLU engines have problems with the classification of some particular intents, which do end up being completely misclassified (zero accuracies and F1-scores). These intents do not have enough expressions in the training data. Next, we aggregate performance metrics per chatbot and outline these statistics in the boxplot below. As before, the first figure denotes our findings obtained from the Dutch expressions while the second one is representable of the French chatbots.
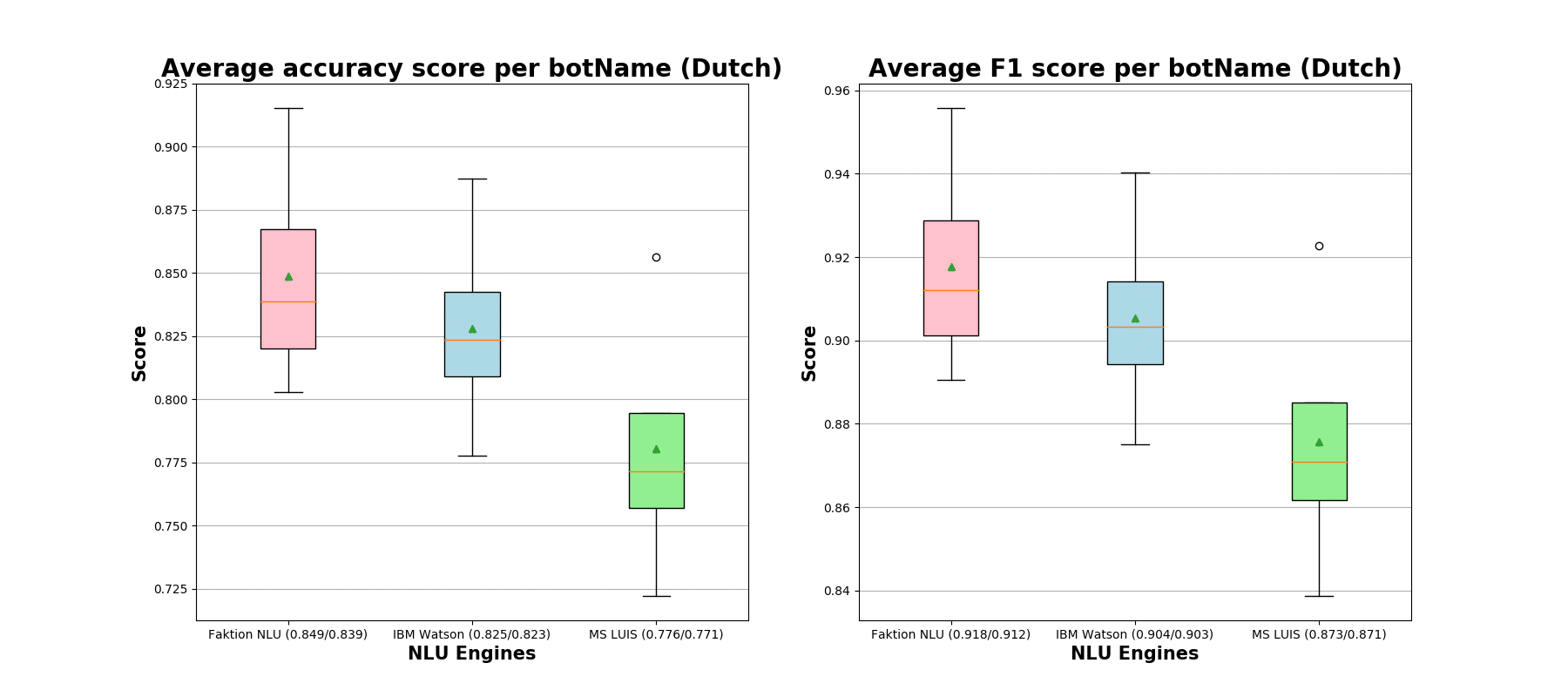
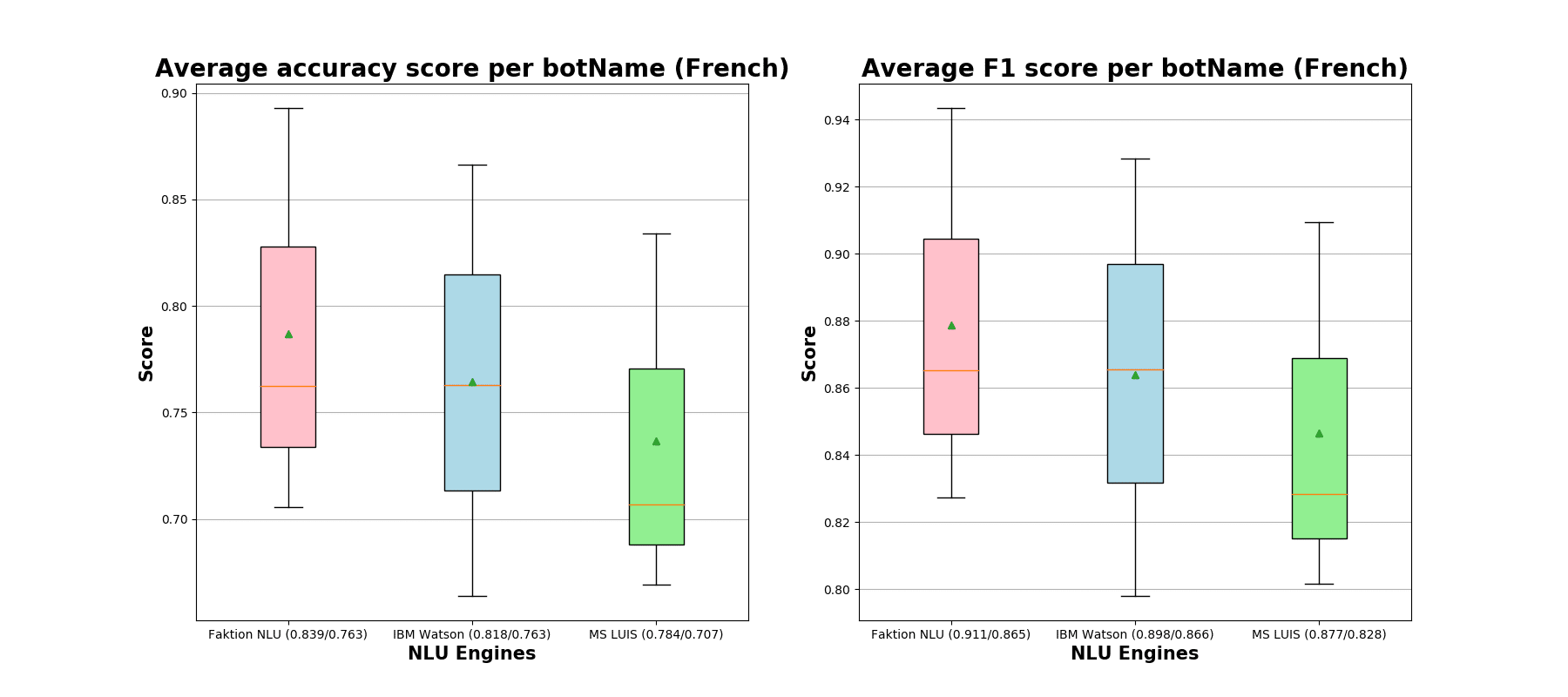
We still observe a predominant supremacy of our home-brewed NLU engine in comparison to LUIS and IBM Watson. This is well-aligned with our production day-to-day classification performance findings.
Discussion and conclusion
In this small blog-post, we discussed NLU systems for languages that are not often (if ever) taken into consideration for benchmarking: Dutch and French. We have demonstrated that a mixture of right Machine/Deep Learning, Natural Language Understanding, and domain-specific expertise can lead to a significant boost in performance.
Our empirical findings and obtained performance evaluations do confirm that even a small AI-focused company can outperform giants of the industry, having in mind customer needs and the right blend of technical and domain expertise in the hands of a highly devoted team of engineers and data scientists.
* an allegory to Defending the Undefendable
